Автоматическая озвучка на английском
Качество генерации синтетического компьютерного голоса в последнее время возросло настолько, что я не удержался от экспериментов с автоматическим созданием английской аудио-дорожки для youtube роликов.
Имеем на входе субтитры, переводим, а на выходе получаем голосовую озвучку, где и не каждый поймет, что это говорит робот. :)
https://github.com/KMiNT21/subtitles-to-audio-track
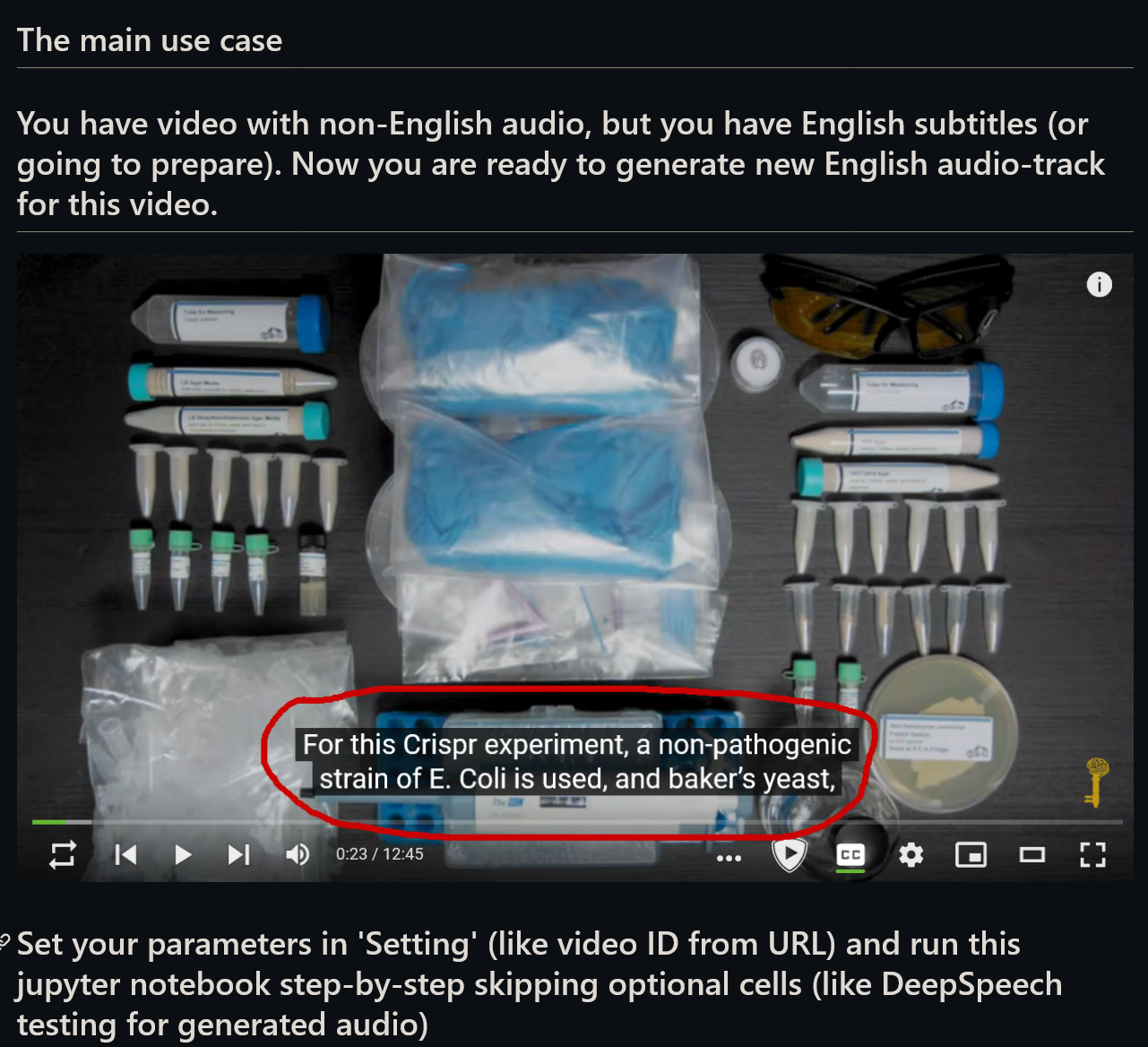
В общем, схватился за Jupyter Notebook, TSS от Mozilla и начал активно прожаривать свою видео-карту мозилловской нейросеткой.
Больше всего заморочек было с перестройкой субтитров. Оказалось, что универсальных решений быть не может. В адекватном переводе могут отсутствовать не только отдельные предложения, но даже и целые блоки. И все это надо перепривязать к временным точкам, которые в любом случае для английского языка будут другие. Короче, над алгоритмом пришлось поломать голову.
А чтобы ломать ее было не так больно, пришлось сделать визуализацию через matplotlib (а точнее, seaborn heatmap). Вот так выводил временную матрицу с текстовыми и цветовыми метками отдельных предложений (т.е на сначала вся озвучка заполняет все свободное место “слева” на временной шкале)
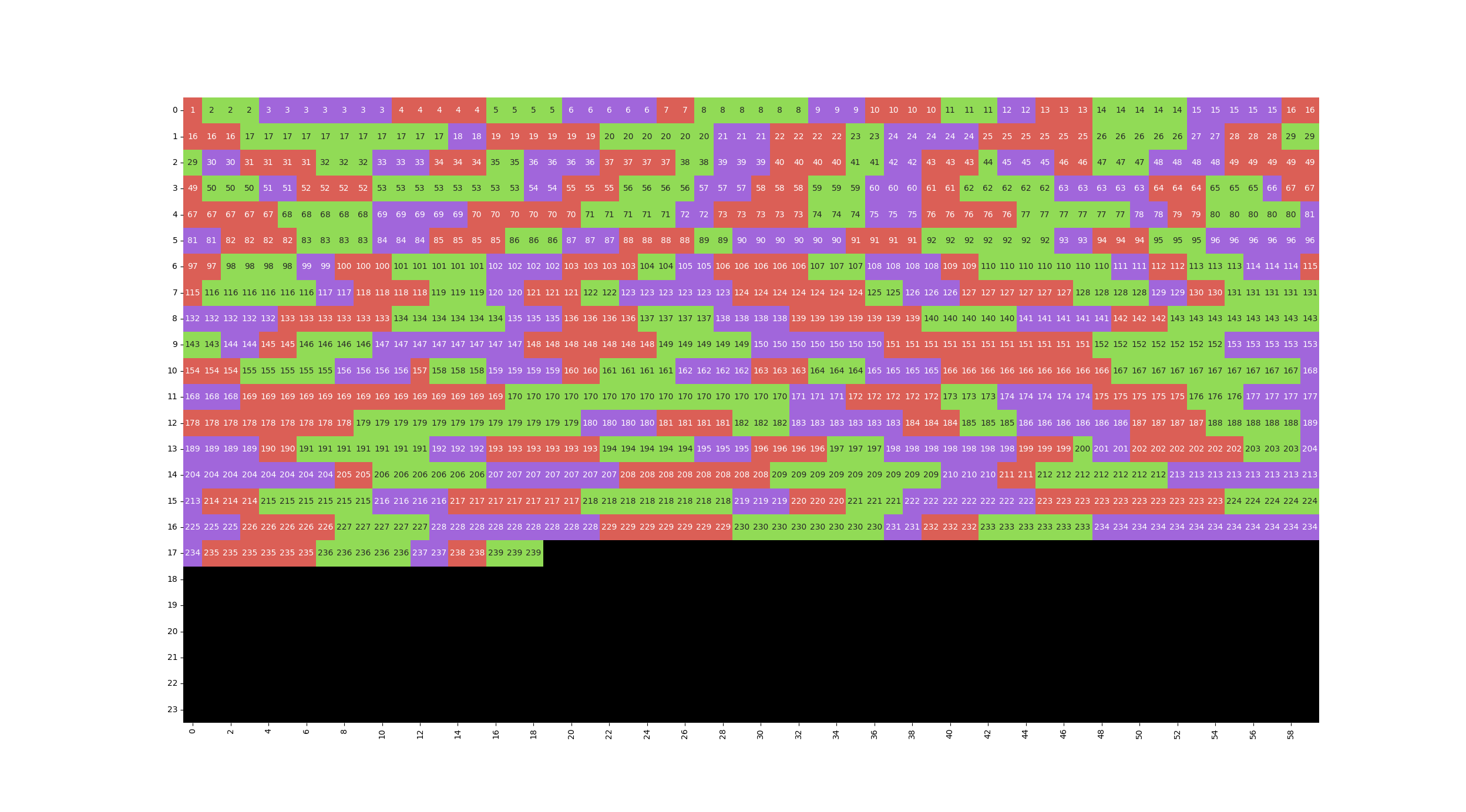
И затем смотрел, как алгоритм расставил это “на временной шкале”, чтобы выловить все косяки.
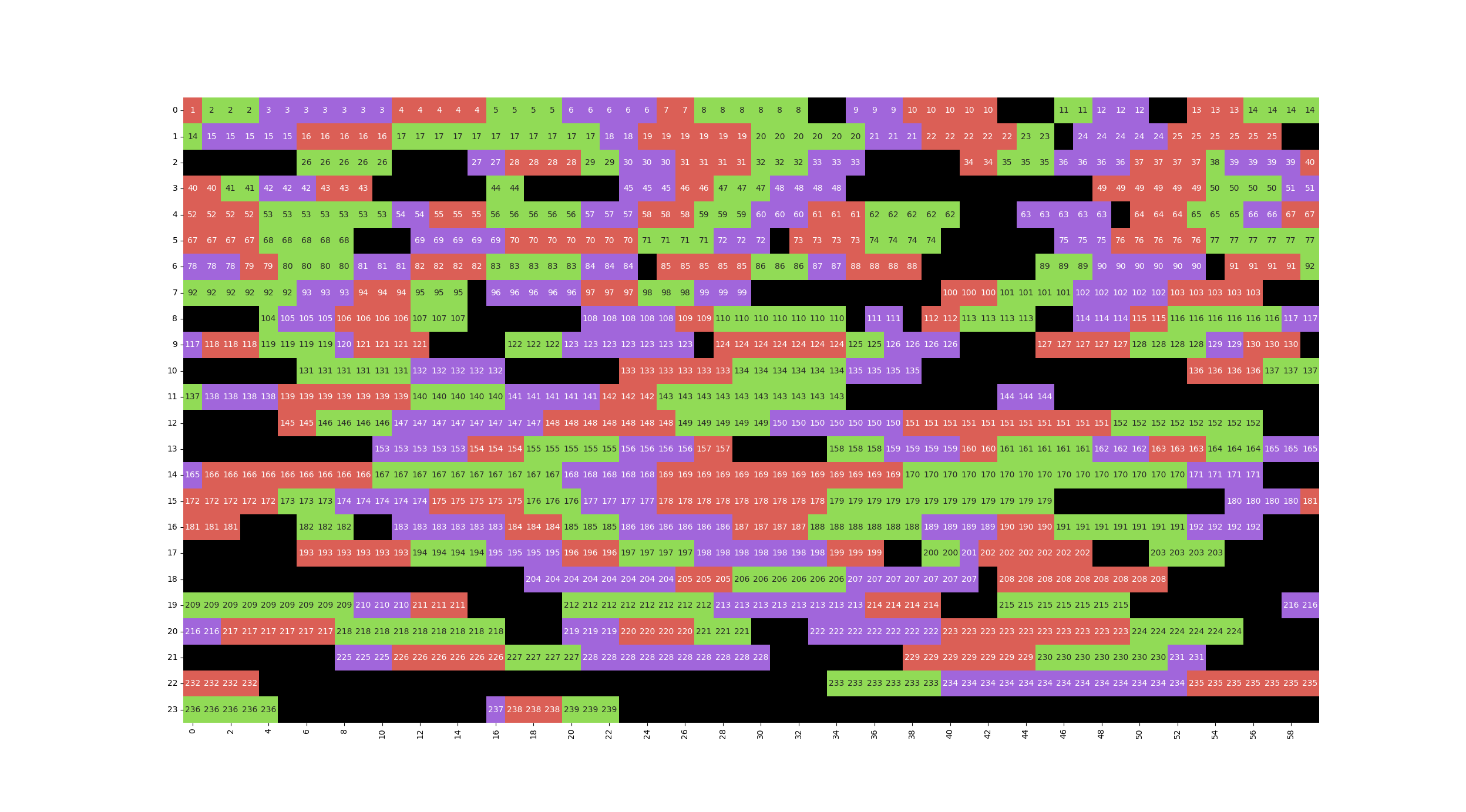
Само собой, если озвучку нужно привязать к конкретным лицам в кадре, то тут только вручную в видео-редакторе привязывать отдельные предложения, которые получаются на выходе нейросети в виде wav файлов в папке проекта.
Но для какого-нибудь закадрового текста все выходит отлично. Жаль только, что на момент экспериментов доступен только женский голос такого уровня качества (модель Tacotron2 DDC).
Кстати, столкнулся с тем, что все интересные мне модели спотыкались на одном длинном предложении и обрывали его в самом начале (проблема с attentions). Как я ни тюнинговал, вылечить это не удалось. Решил это упрощением и разбитием длинных предложений.
А для проверки я еще попробовал нейросетку DeepSpeech. Как оказалось, она все еще фигово распознает текст даже для этого синтетического голоса. :) Но мне хватило и такого качества, чтобы автоматически вылавливать “битые” предложения, пока тестировал.
В общем, система работает отлично. Но для нормальных роликов и перевод нужен качественный. Я даже со своим английским вижу кучу косяков Google Translate (хоть там и нейросетка). Экспериментировал с подачей результата на всякие нейросетевые рерайтеры типа Copy.ai, чтобы те исправляли корявый перевод длинных разговорных предложений, но пока они тоже с этим не могут справиться. Вот если бы были доступны “исправлялки” уровня GPT, то они бы точно дали сразу результат. :) Ну ничего, подождем.