Программерский детектив
Итак, пока я тут доделал парсер-конвертер html-статей в набор предложений (с помощью BeautifulSoup4, различных регулярок и NLTK.tokenize - для подачи на вход нейросети на TensorFlow) и доволен чистотой результата, решил сделать паузу и, все-таки, написать эту забавную и поучительную историю.
Программерский детектив
Приятно наблюдать как недавно собранный компьютер “перемалывает” всеми 8(16) ядрами нужную мне задачу. Вот только я не ожидал, что придется перезапускать это так много раз.
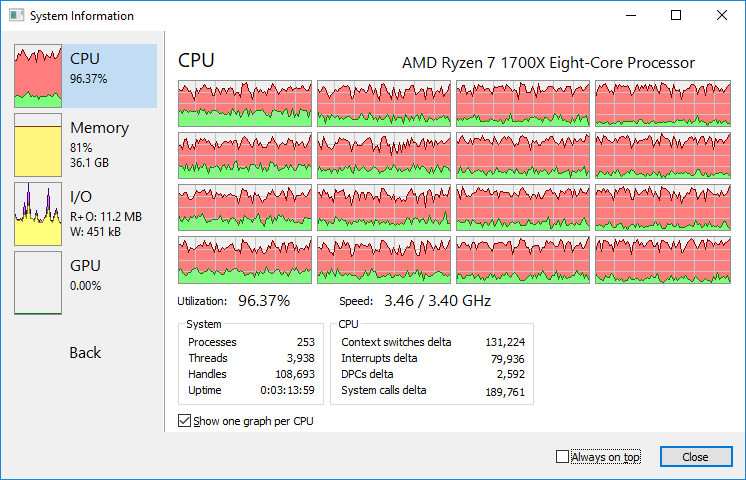
В последний раз так мозг закипал, наверное, только когда нужно было сделать динамический пересчет релокейшенов загруженного модуля win32. И это было так давно, что я уже не могу вспомнить что конкретно я там делал.
А вот в этот раз сильно забуксовал с библиотекой поиска схожих (релевантных) документов-статей (#python, #gensim). То у меня изначально никак не хотела работать цепочка трансформации векторов в разные пространства bag-of-words -> TfIdf -> LSI (точнее, не получалось правильно добавлять новые документы после первичной инициализации). То потом за время эксплуатации не раз приходилось все сбрасывать и инициализировать заново (а, например, самый “тяжелый” набор данных пересчитывается больше 2 часов при полной загрузке ЦПУ).
Замучали периодические segfaults - питоновский процесс просто вырубался без предупреждений, вызывая рассинхрон “базы” (корпус документов и соответствующий ему по кол-ву список идентификаторов последних). В течении многих дней я все это и обвешивал логами чуть ли не после каждой операции, и дополнительные проверки ввел, чтобы при сбое в наборе данных не происходила попытка их обработать…
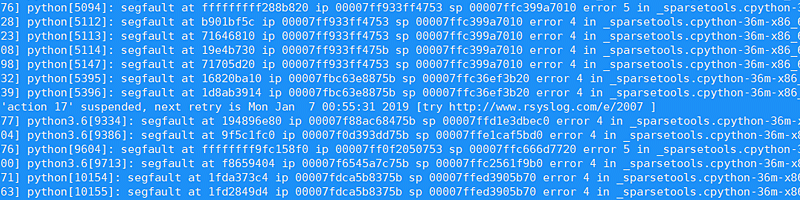
Но в итоге, наконец, получил очередной сбой, в котором размер корпуса (Market Matrix формат) по кол-ву документов совпадал с размером списка добавленных ID-шек статей, то при этом стабильно каждый запуск завершался segfault. Вот тут стало все уже интересней.
Первым делом собрал (как всегда - с боями) из исходников самую последниюю версию питона - 3.7, попутно обновив кучу библиотек на Debian Jessie (для этого даже пришлось подключить Debian Testing репозиторий - хорошо хоть ничего не сломалось.) Картина не поменялась. Пришлось искать как это можно отдебажить.
По строчке в /var/log/messages понять ничего было нельзя кроме того, что это был сбой в .so-модуле sparsetools библиотеки ScyPy. По примерам со stackoverflow с помощью gdb вышло только уточнить то, что происходил сбой в стандартной си-библиотеке.
В общем, не оставалось ничего другого, как нажать F3 и глазами всматриваться в строчки корпуса, пытаясь понять что с ним не так, благо формат у него подходящий для чтения человеком. В отличии от файла-словаря (word->id). Но тот мне и не нужен был, так как не менялся после первичной инициализации исходным набором документов, что подтверждала дата его модификации.
...
25833 34815 1.0
25833 39749 1.0
25833 54151 3.0
25833 56543 2.0
25833 60926 2.0
25834 4 5.0
25834 14 1.0
25834 20 4.0
25834 22 1.0
...Через какое-то время на глаза попалась очень странная строка. В ней было число-идентификатор (слова в словаре) какое-то слишком большое. Перепроверил - так и есть. У меня словарь меньше. Вот сюрпрайз так сюрпрайз. Дальше я уже методом “reverse engineering” начал проверять “слепки” документов в корпусе на соответствие реальным статьям. Т.е. получал список слов по их ID-шкам в dictionary, получал ID документа и всматривался в текст на предмет наличия этих слов.
И вот все совпадало ровно до этого сбойного документа. В нем набор слов выходил каким-то странным - найти их в исходном тексте статьи я не мог. Удивление мое все нарастало. Немного еще подумав, я наудачу начал перебирать наборы данных других сайтов, обращая внимание на те, размеры словарей в которых были больше интересующего меня значения.
Дальше - банальный поиск по файлу корпуса (corpus.mm), и я нахожу полное вхождение того “сбойного” документа в совершенно другой базе! ШОК… Сижу и думаю - как так могло получиться-то… Тем более, что пути везде полные указываются у меня. Полез снова в свои исходники, всматриваюсь…
temp_file = get_tmpfile('corpus-mm-last_new_doc.tmp')
corpora.MmCorpus.serialize(temp_file, [vec_bow])
new_docs = corpora.MmCorpus(temp_file)
new_corpus_mm = list(itertools.chain(corpus_mm, new_docs))Тут, наконец, приходит озарение. Я как вставил изначально вызов функции get_tmpfile() из gensim.test.utils, так больше и не вспоминал даже. Эта функция просто формирует путь к папке для временных файлов, т.е. в моем случае это формировало путь /var/tmp/corpus-mm-last_new_doc.tmp Этот файл нужен лишь на короткое время для добавления документа к текущему корпусу. Но, как оказалось, в какие-то редкие моменты времени на моих VPS-ках все так замедляется / подвисает, что происходит накладка работы скриптов разных сайтов и перезапись в тот же временный файл до его отработки. :)
В общем, загадка, наконец, разгадана. Убрал использование общей папки /tmp/ - больше ошибок не наблюдается. Заодно решил заменить new_corpus_mm = list(itertools.chain(corpus_mm, new_docs)) на new_corpus_mm = itertools.chain(corpus_mm, new_docs) для экономии памяти. И вот недавно смотрю - все корпуса везде у меня обнулились. Хорошо, что если не сбоев, то мне и корпуса не нужны. Лишь бы similarity-индексы целыми были. :) Зря я преобразование в list() убрал - не умеет сериализатор gensim.corpora с итератором работать. Эх…
Впрочем, это уже совсем другая история.